Batch Processing can be a complex beast to understand. Many a MuleSoft developer has fallen foul of the Batch. To the uninitiated, the Mule may appear anything from vaguely stubborn to downright obstinate when working with batch jobs for the first time.
As is always the case, the Mule is not being obstinate; you just need to learn how to Whisper properly to get the best out of your Mule solution.
Below is a list of the common rookie errors and incorrect assumptions made by developers when working with Batch jobs.
Adding a Batch Job to a Sub-Flow
In the interests of strict accuracy, I should say, ‘Attempting to add a batch job to a Sub-Flow.’
… because it can’t be done.
In this scenario, a developer might add a sub-flow to their configuration file, and then try to drag a Batch Job component onto that sub-flow. After a few failed attempts, the frustration begins to set in.
The reason this can’t be done is because Sub-Flows are, by nature, synchronous. In other words, any flow that calls a sub-flow will wait until that Sub-Flow completes before it continues on its way.
Conversely, a Batch-Job is, by nature, asynchronous. Putting an asynchronous scope inside a synchronous one makes no sense.
Solution
Create a new Flow (instead of a Sub-Flow) and add the Batch Job component to that. Then call the Flow from wherever you originally intended. The Mule will gladly comply with the new, more sensible, approach.
Evaluating Payload after Batch Job completion
This is a common rookie error. As a developer, the assumption is that your flow will wait for the batch job to complete before continuing on its merry way. Incorrect! As mentioned previously, Batch jobs run asynchronously. As such, you Flow will not waste threads, memory and CPU resources waiting for a batch job that may take hours to complete. It initiates the batch and moves on.
So, in the scenario below…
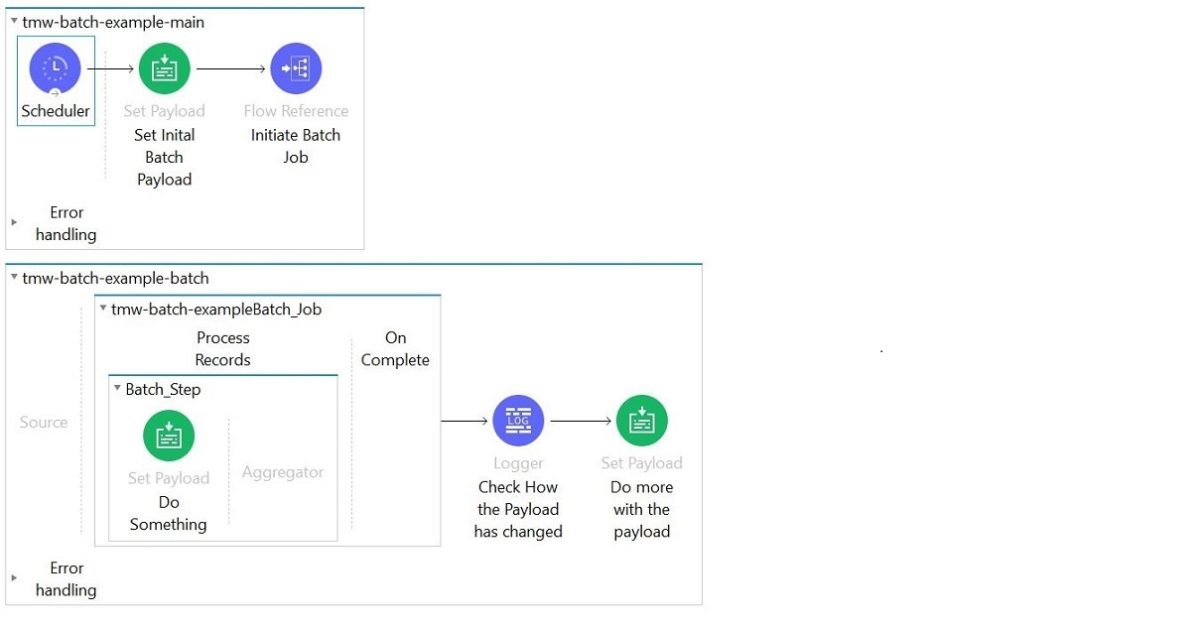
… the rookie is in for a surprise on several counts.
- The payload at the above logger component and its subsequent set-payload component bears no resemblance to the payload passed into the batch job. In fact, the most likely outcome is a Runtime error.
- Assuming the flow actually runs… if the person who created this flow pays attention to the logs, they would notice that the Check How the Payload has Changed log is written to the log mere seconds after the flow was initiated — even if the batch job itself runs for hours.
- If you added a Logger component inside the Batch_Step above, say, just before Do Something, and then watch your log file you will see the following:
- One of the first logs to appear will be the Check How the Payload has Changed log
- After that you will see a myriad of logs generated inside your Batch_Step
That is asynchronous processing.
Solution
If you want to do something when the batch job actually completes, you need to do that processing in the On Complete scope inside the Batch Job.
Expecting the Payload in the On Complete Scope
To solve the above issue, the intrepid Mule rookie is likely to try shifting their flow components from the flow, and into the Batch Job’s On Complete scope; the assumption being that the Batch Job will aggregate the individual batches back into one giant output payload.
But, in the example below…

… the flow seems to act strangely.
This is because of an ill-informed assumption on the rookie’s part. The original payload is already gone. In fact, an examination of the resulting payload in the On Complete scope will reveal an object that simply tells you how good, bad or ugly your Batch Job was. This will include the total number of batches, along with the number of successful vs failed batches your job encountered. No original or transformed payload data to be found.
While this may not make sense at first blush (from an Application Development perspective), it makes perfect sense to the Mule, in its Integration paradigm. The reason you opted for a Batch Job in the first place is because you were dealing with large data volumes.
A Batch job takes care of all those pesky Out of Memory Exceptions one might usually encounter in this type of scenario. Having done its job and handled your massive data volumes without breaking a sweat, why would the Mule now choose to trip at the last post, so to speak, by recompiling all that data in memory and then raising the inevitable Out of Memory Exception that would result?
Solution
Don’t assume you will see your payload in a single place on job completion; you won’t. If you need to reassemble your payload, you need to do it inside your batch job, as you go. Write the output to a file, add it to a database, or forward it to an external API. After all, that is what a Batch Job is for.
Assuming Batch Jobs Maintain State
There are several things a rookie might do when making this assumption. The most common is creating a counter at the beginning of a batch, and then incrementing the variable on each iteration. Let’s imagine some one does this on the below batch job and initiates the value to zero.
So, in the following example…
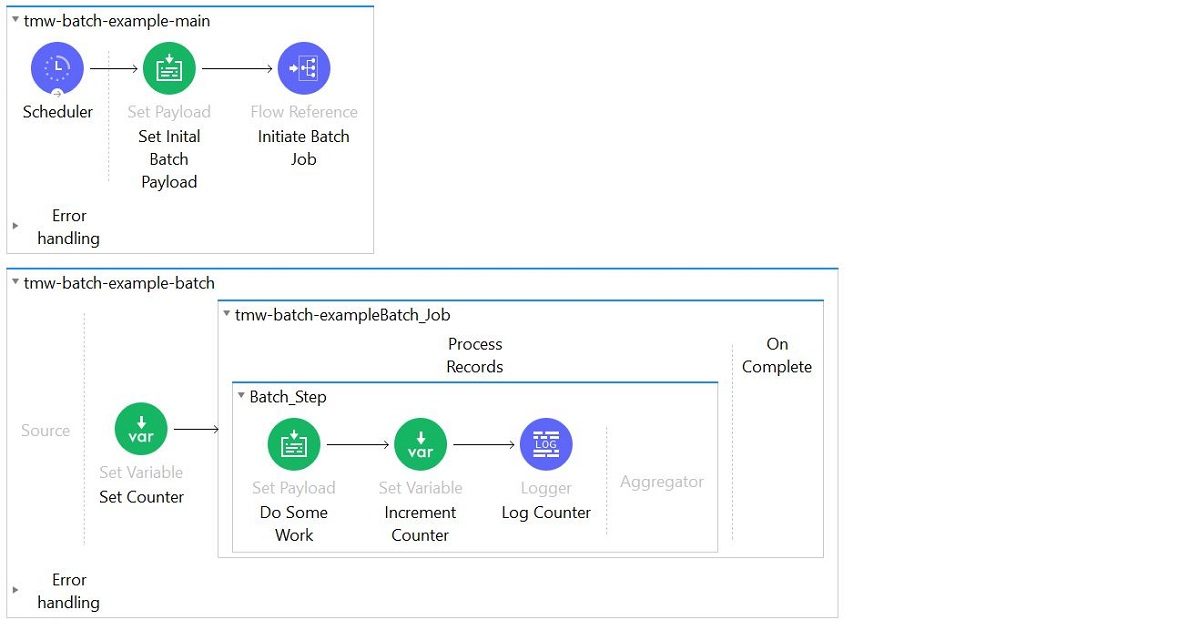
… get ready for a lot of Counter = 1 records in your log file.
Another common mistake made off the back of this assumption is to create an Array variable out the outset, and then append elements to the array on each iteration. This to compensate for the fact that the transformed payload is not propagated to the On Complete scope. This simply doesn’t work as no state is maintained between batch iterations.
This behaviour appears to be the most confusing for developers who are new to Mule. It is also the one that particularly annoys the more experienced application developers as it simply makes no sense, on the face of it.
Solution
To those annoyed developers, I say there is no point raging against the machine. It is what it is. Accept it. You don’t get all the power of memory management out of the box without a trade-off — and this is the trade-off. If every batch runs in a separate thread and memory is managed out of the box, you can’t then expect the Runtime to support an In-Memory feature that would negate all of that power and actually generate an Out of Memory Exception.
The rule is simple. Think of a Batch Job like Vegas — what happens in Vegas stays in Vegas. You can change variables all you want within a single batch iteration, and reference those changes as you go. But when that iteration completes, it is as if those changes never happened.
If you need a counter, or want to maintain state in some other way, then use a For-Each scope instead of a Batch Job. That will give you all the state you want. But then don’t be surprised when your For-Each scope chokes on the 1GB file you’re trying to process. It’s horses (or Mules) for courses.
Mule Whisperers know how to pick the right tool for a given job — and then work within, or around, the constraints imposed by that choice.