There is far more to writing Unit Tests — or MUnit Tests, as they are called in Mule — than mere code coverage. If we are going to test our code, as we should, the tests we write need to be meaningful. A proper Test-Driven approach will impact not only the tests we write, as developers, but also the very structure of the code within the Mule Flows we aim to test.
There are many ways to write a bad test. These can range from pointless tests to downright dangerous ones that offer stakeholders a false sense of security.
Below are a few of the rookie mistakes that inexperienced ‘Muleys’ often make in an effort to meet the non-functional requirements imposed on them by well-meaning project stakeholders.
Mistake #1 — Focusing only on Code-coverage
Code coverage is a useful metric that many CI/CD tools will measure as part of their build criteria. The trouble is, it is a rather blunt instrument. For instance, it would be very easy to implement all your tests as follows:
- Invoke my-mule-flow (from MUnit)
- Assert true == true
- End Test
The above scenario will result in massive Code-Coverage, and it will pass every time! The CI/CD tools will tally up the code coverage and pass the build, moving it on to deployment. The trouble is, tests like these are not worth even the few bytes of storage they take up in a source control system.
Of course, the above test algorithm is a developer’s fairly brazen refusal to do any real testing; most hard-working folk would never dream of intentionally writing such a test. A more common approach is to focus on the internal processing flows. In this scenario, the developer will invoke these internal flows (one test per flow), implement a handful of arbitrary Assertions, and rack the test up as a pass.
Put under the microscope, however, it will often turn out that these tests amount to little more than the ridiculous Test Algorithm described above.
Solution
In order to test internal processing flows thoroughly, a developer first needs to understand all of the core variations in the inbound Payload, Variables and Attributes of a message — and then it needs to test for each of them. Only then can we say that we have tested the flow thoroughly.
Mistake #2 — Skipping the Minutiae in complex flows
This is a common rookie error. Consider a complex flow, particularly one that contains several intricate Transforms to the payload along its journey, like the flow below. Developers, keen to maintain their code coverage, might be tempted to create a simple test that runs this flow and then confirms that the FTP server sent a valid response and that the file was successfully transferred
So, in this scenario…
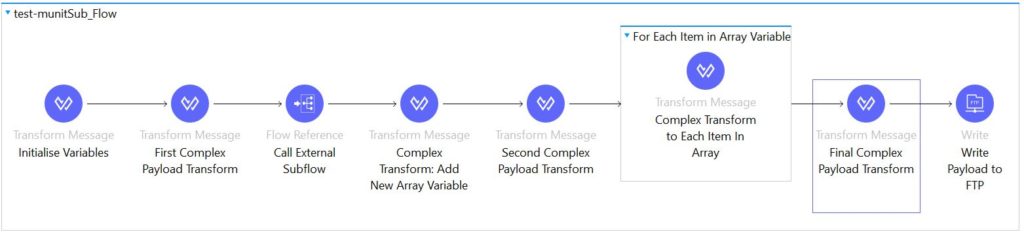
… the Mule rookie might write their test as follows:
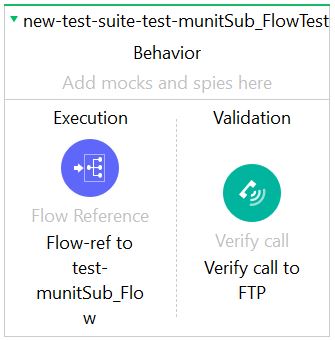
In this test, the developer assumes that, if the FTP call is made successfully, then the flow worked. Of course, this is only partially true. While we know that the flow ran successfully and that we transferred our payload to the remote FTP server, we have no clue as to what the payload looks like on the target; if the above flow posted a file with nothing more than “Hello World” in the payload, this test would still pass.
Frankly, this type of test offers little value.
Solution
First, we have to recognise where our tests on the above flow need to focus; the Transforms. It is these components that contain the lion’s share of our code logic. Testing these complex transforms is no easy task in the above flow, as they are largely inaccessible to our MUnit tests when creating bog-standard Test Suite, as shown in many standard MUnit tutorials.
The best way to test these components is to externalise the Dataweave scripts in files that can be tested directly, outside of the flow in which they reside. This is clean but, arguably, a little complex to implement. The good news is that you can retrofit this quite easily, assuming you have an existing project with a myriad of Transforms scattered throughout your Mule Configuration files. I cover this in a separate post; check out The Secret Art of Testing Transform Components for more details on this.
Mistake #3 — Testing other people’s Code
This is, without doubt, the single most common mistake I see in MUnit test suites. Usually, the code we want to test looks something like this:
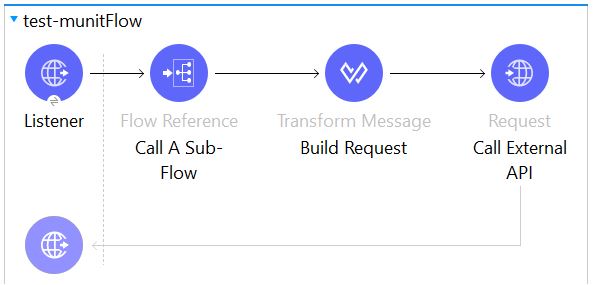
… and the corresponding test looks something like:

This all works perfectly the first few times you run this test. Then, two months in, it suddenly begins to fail for some unknown reason. Your code has not changed, but the response appears to be different. Several hours of investigation followed by a few calls to the external team who developed and manages that API reveals that they had a change request and have now changed some part of the response on that particular call.
‘It’s a small change,’ they say, ‘and it won’t impact downstream systems at all.’
This may be true, but it has already impacted your test!
In this scenario, the developer usually dutifully goes back and updates the test to check for the new response — and now the test passes again…
… until, the next time.
Several weeks pass and, suddenly, it fails for yet another inexplicable reason. A lengthy investigation reveals that the external service has gone off piste, for some reason. Yet another call to the external team reveals that, this time, a new developer joined the team and checked in a change that they shouldn’t have. Nobody on that team noticed that their latest change broke this particular response, because that team hasn’t bothered to write any Unit Tests of their own.
And why should they? After all, you’re doing it all for them!
Solution
Put the “Unit” back into MUnit and stop testing external systems! A closer examination of the above test reveals that the only thing it actually tests is, in fact, the response from a remote server. This is something over which your process has no control; so why test it?
In this scenario, your tests should focus on the Sub-Flow and the Transform, to ensure that you are building an appropriate request that adheres to the project requirements and specification. Any response from the third-party system in this context is irrelevant. Let the external team test their own code!
This is where the Mock component takes centre-stage. Take a look at the flow below:
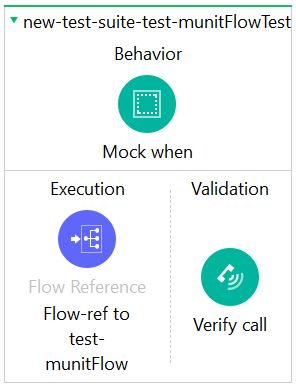
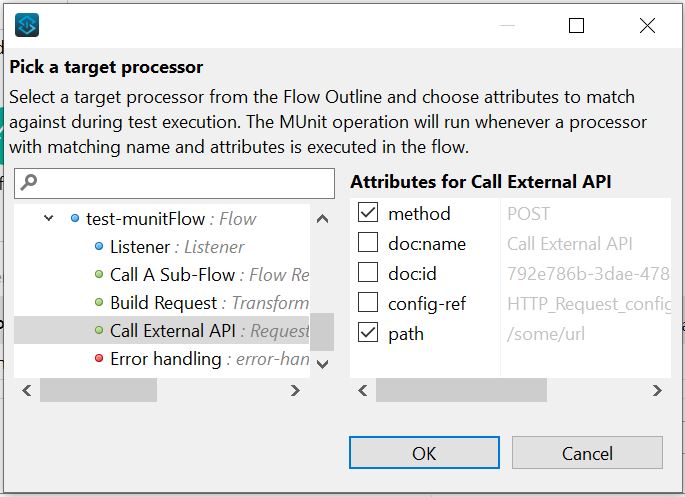
In this scenario, we create a Mock that intercepts our calls to the third-party system, and sends a predefined response back to the calling code. To configure your Mock Component, you need to first identify the Processor you need to Mock. In this case that is the Call External API Request component. To do this, click the Pick Processor button in the component’s config pane:

Then find, and double-click the relevant Processor in the left-hand pane. This will open the Attributes for that component. Check the necessary Attributes that define this component call. Then click OK.
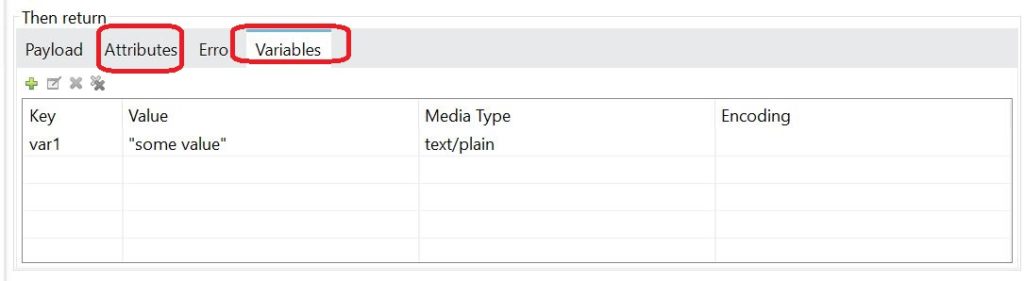
Finally, you can configure a static response in the Then Return text box as required:
#[
{
"field1": "My expected response",
"field2": "Next expected response"
}
]
WHISPER: This is one of those (fairly rare) form fields that does not have fx toggle to switch between static text and Dataweave script. Remember to add the #[ … ] wrapper manually to tell Mule that this is a script rather than static text. It is not immediately apparent that this is required, so can be confusing if you don’t know to do it.
You are also able to configure Variables and Attributes, if required.
Now, when you run your test, your new Mock component will intercept the external call and return the response that you defined for your test, rather than leaving your Test Suite at the mercy of some external system over which you have no control.
This leaves the developer free to test the only code that matters in this context — the Mule Flows.
Mistake #4 — Testing Data instead of Code
This is a variation on Testing Other People’s Code, as described above. The only difference, in this instance, is that, rather than dealing with problems on an external API, you are dealing with changing and unstable Data that affects your tests. Data in this context is usually a Development instance of an external Database. However, it could just as easily be a flat file on a remote FTP server or a Network drive.
These external databases and files are usually managed by people outside your Integration Development Team — and those people often refresh, delete or otherwise “cleanse” their data at random intervals as they see fit. It is also highly likely that your system shares that data store with one or more other systems that also Create, Update or Delete records at random, as part of their own Software Development Lifecycle.
In short, you cannot trust this external data and you cannot expect it to be in a given state every time you run your test.
And yet, all too many developers insist on writing tests that read, update and delete this external data — and then write Asserts that assume the source data was in a given state when the test started. Then they wonder why their tests fail at random.
The rule is simple; if you are constantly rewriting your tests to account for changes in an external data source, then you are testing external data instead of your code.
Solution
The solution here is the same as the one above. Create a Mock component that intercepts the call to the external Data Source and return a predefined response that conforms to the current valid data state. Then test your code to ensure that it deals with that data as expected.
Conclusion
As already stated in the title, Testing and Test-Driven Development (TDD) can be a dark art, at times. There are a lot of choppy waters to navigate. However, avoiding the above pitfalls will take you a long way toward creating more effective, and comprehensive, Test Plans for your MuleSoft projects.
Happy Testing!